
概要
OracleからRedshiftへの移行でAWS SCTを使う時に、こういうMigration ruleを書いておいたほうがいいんじゃない、というもののメモです。
背景
以下の記事の派生です。SCT自体の使い方は元記事をご参照ください。

やりかた
標準のMigration ruleの確認 (数値型)
Oracleで次のような定義をしたテーブルがあります。
CREATE TABLE numbers_table (
id NUMBER PRIMARY KEY,
num1 number(5),
num2 number(10),
num3 number(38),
num4 number(10,5),
num5 number(10,0),
num6 number(*,0),
num7 number(*,5)
);SCTの標準ルールで変換すると次のようになります。
CREATE TABLE numbers_table(
id NUMERIC(38,18) ENCODE AZ64 NOT NULL,
num1 INTEGER ENCODE AZ64,
num2 BIGINT ENCODE AZ64,
num3 NUMERIC ENCODE AZ64,
num4 NUMERIC(10,5) ENCODE AZ64,
num5 BIGINT ENCODE AZ64,
num6 NUMERIC(38,0) ENCODE AZ64,
num7 NUMERIC(38,5) ENCODE AZ64
) DISTSTYLE AUTO SORTKEY AUTO;1つずつ見ていきましょう。
num1 number(5)
Oracleで整数5桁で定義されたカラムです。これはINTEGER型として変換されています。
小数部がない場合は整数型の中から適切な型が選ばれるようになっています。
https://docs.aws.amazon.com/ja_jp/redshift/latest/dg/r_Numeric_types201.html#r_Numeric_types201-integer-types
名前 ストレージ 範囲 SMALLINT または INT2 2 バイト -32768~+32767 INTEGER、INT、または INT4 4 バイト -2147483648~+2147483647 BIGINT または INT8 8 バイト -9223372036854775808~9223372036854775807
num2 number(10)
Oracleで整数10桁で定義されたカラムです。INTEGER型で収まらなくなったのでBIGINT型に変換されています。
num3 number(38)
Oracleで整数38桁で定義されたカラムです。BIGINT型でも収まらない場合、NUMERIC型になります。
num3 NUMERIC ENCODE AZ64,NUMERIC型はOracleのNUMBER型に近い型で、精度をユーザーが定義できます。
次の形で定義します。
numeric(precision, scale)precision
値全体での有効な桁の合計。小数点の両側の桁数。例えば、数値
48.2891の場合は精度が 6、スケールが 4 となります。指定がない場合、デフォルトの精度は 18 です。最大精度は 38 です。入力値で小数点の左側の桁数が、列の精度から列のスケールを引いて得られた桁数を超えている場合、入力値を列にコピー (または挿入も更新も) することはできません。このルールは、列の定義を外れるすべての値に適用されます。例えば、numeric(5,2)列の値の許容範囲は、-999.99~999.99です。scale
小数点の右側に位置する、値の小数部における小数の桁数です。整数のスケールはゼロです。列の仕様では、スケール値は精度値以下である必要があります。指定がなければ、デフォルトのスケールは 0 です。最大スケールは 37 です。テーブルにロードされた入力値のスケールが列のスケールより大きい場合、値は指定されたスケールに丸められます。SALES テーブルの PRICEPAID 列が DECIMAL(8,2) 列である場合を例にとります。DECIMAL(8,4) の値を PRICEPAID 列に挿入すると、値のスケールは 2 に丸められます。
https://docs.aws.amazon.com/ja_jp/redshift/latest/dg/r_Numeric_types201.html#r_Numeric_types201-decimal-or-numeric-type
上の赤字の箇所のとおり、precisionもscaleも指定しない場合はnumeric(18,0)と同じ精度になります。元々Oracleでnumber(38)で定義しているのでこれだと精度が落ちます。おそらくSCTのバグではないかと思います。
num4 number(10,5)
Oracleで全体で10桁、そのうち小数部5桁で定義されたカラムです。これはNUMERIC型のnumeric(10,5)として変換されています。
num5 number(10,0)
Oracleで全体で10桁、そのうち小数部0桁で定義されたカラムです。これはBIGINT型として変換されています。number(10)で定義する時と同じ結果になります。
num6 number(*,0)
Oracleでは精度(全体の桁数)を指定しないことができます。その場合、number(38, <scale>)として扱われます。num6の場合は、全体で38桁、そのうち小数部0桁で定義されたカラムです。これはNUMERIC型のnumeric(38,0)として変換されています。
num7 number(*,5)
精度指定なしで小数部5桁にしました。全体で38桁、そのうち小数部5桁で定義されたカラムとなりす。これはNUMERIC型のnumeric(38,5)として変換されています。
追加するMigration rule (数値型)
標準のルールを踏まえて、次のルールを追加することにしました。
Migration ruleは上から順番に適用されるっぽいので順番を変えると意図しない動作になります。
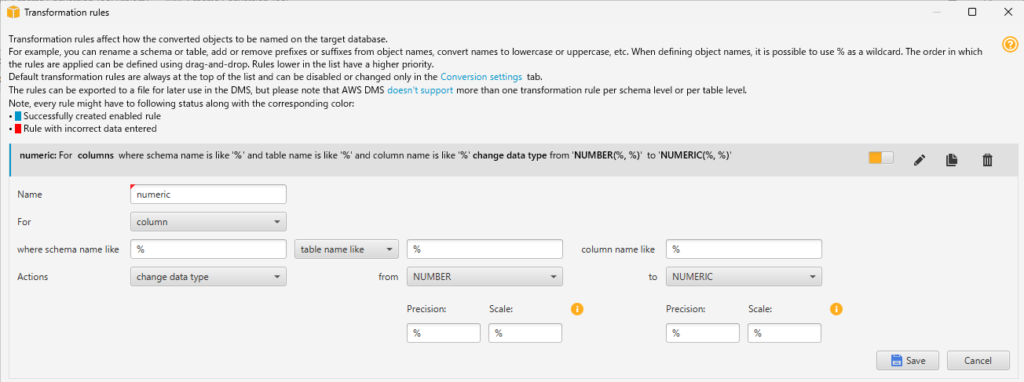
- number(%, %)の場合は、numeric(%,%)に変換する
- numberを同じ精度、同じスケールのnumericに変換します。
- このルールによって整数型に変換されていた箇所も全てnumericになります。シビアにパフォーマンスを求める環境でない限り、この方が可読性がよいと考えました。(別に整数型でもよい)
- 標準ルールでバグっぽい動きをしていたnumber(38)は、このルールによりnumeric(38,0)に変換されるようになります。
- 副作用として、精度指定をしないnumber(*,5)のようなカラムが精度、スケールともに指定のないnumericになります。
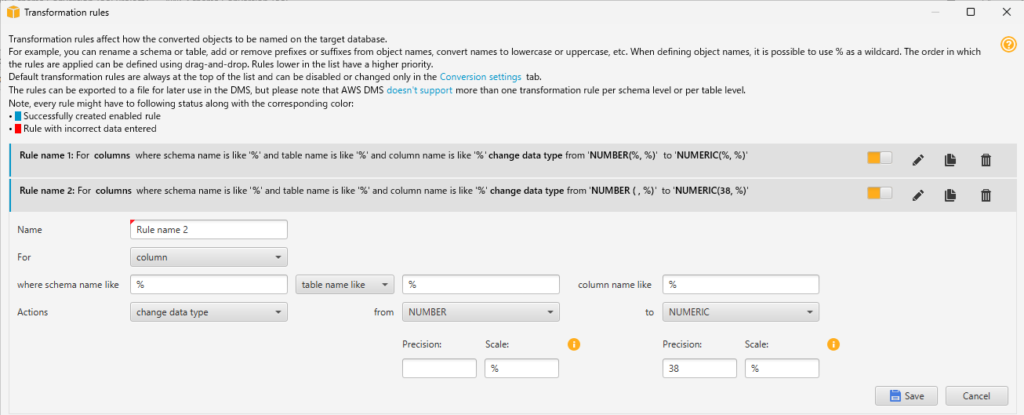
- number(, %)の場合は、numeric(38,%)に変換する
- ルール1の副作用を打ち消すためのルールです。
標準のMigration ruleの確認 (文字列型)
Oracleで次のような定義をしたテーブルがあります。
CREATE TABLE characters_table (
id NUMBER PRIMARY KEY,
char1 char,
char2 char(10),
char3 char(2000),
char4 varchar(1),
char5 varchar(4000)
);SCTの標準ルールで変換すると次のようになります。
CREATE TABLE characters_table(
id NUMERIC(38) ENCODE AZ64 NOT NULL,
char1 CHARACTER VARYING(1) ENCODE LZO,
char2 CHARACTER VARYING(10) ENCODE LZO,
char3 CHARACTER VARYING(2000) ENCODE LZO,
char4 CHARACTER VARYING(1) ENCODE LZO,
char5 CHARACTER VARYING(4000) ENCODE LZO
) DISTSTYLE AUTO SORTKEY AUTO;1つずつ見ていきましょう。
char1 char
Oracleで文字型1桁で定義されたカラムです。これは文字列型であるCHARACTER VARYING型のcharacter variyng(1)として変換されています。
OacleのCHAR型は固定長で、RedshiftのCHARACTER VARYING型は可変長なので末尾の空白が重要なシステムであれば注意が必要です。
char2 char(10)
Oracleで文字型10桁で定義されたカラムです。これはCHARACTER VARYING型のcharacter variyng(10)として変換されています。
char3 char(2000)
Oracleで文字型2000桁で定義されたカラムです。OracleのCHAR型は2000桁が最大です。これはCHARACTER VARYING型のcharacter variyng(2000)として変換されています。
char4 varchar(1)
Oracleで文字列型1桁で定義されたカラムです。CHAR型の時と同じくCHARACTER VARYING型のcharacter variyng(1)として変換されています。
char5 varchar(4000)
Oracleで文字列型4000桁で定義されたカラムです。OracleのVARCHAR型は4000桁が最大です。これはCHARACTER VARYING型のcharacter variyng(4000)として変換されています。
追加するMigration rule (文字列型)
標準のルールを踏まえて、次のルールを追加することにしました。
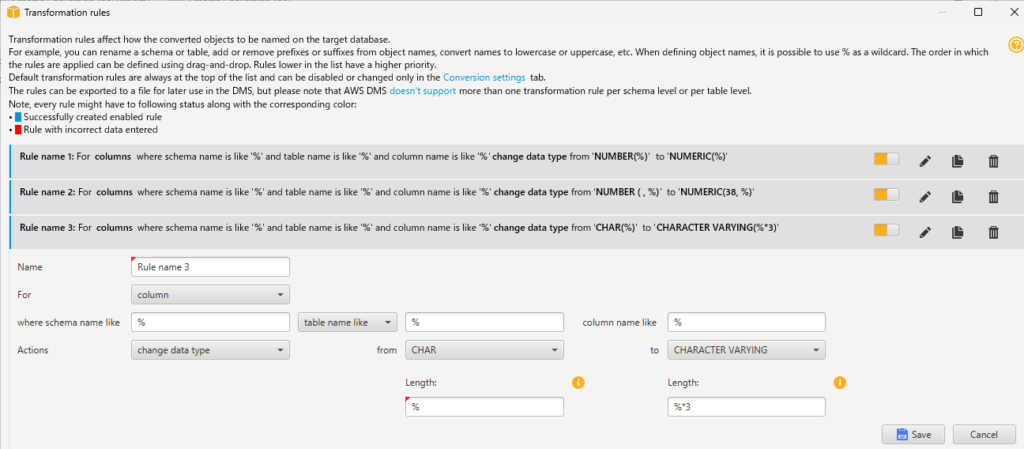
- char(%)の場合は、character varying(%*3)に変換する
- charを元の長さの3倍のcharacter varyingに変換します。
- Redshiftにもchar型が存在しますが、シングルバイト文字しか入れられないためcharacter varying型に変換しています。
- Redshiftは文字コードがUTF8で、日本で使われているOracleはたいがいSJISなので、文字によっては同じ長さにすると収まらない場合があります。(例: 半角カナはSJISだと1バイト、UTF8だと3バイト)
- そのため、移行元に何が入っていても大丈夫なよう、長さを3倍にしています。
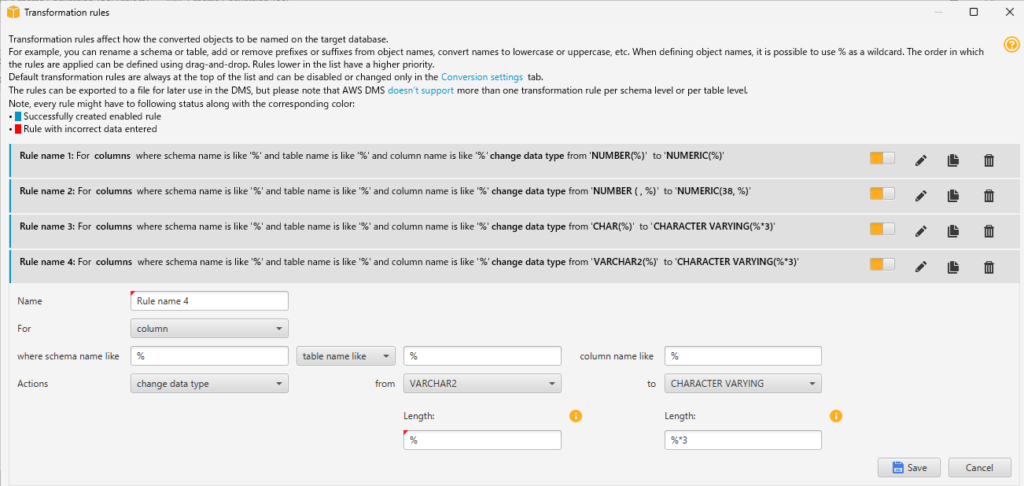
- varchar(%)の場合は、character varying(%*3)に変換する
- CHAR型と同じように長さを3倍にしています。
この設定については正直異論ある方もいるでしょう。3倍にすればその分パフォーマンスも落ちるので。ひとまずデータが移行漏れを起こさないようこのルールでDDLだけ作って、中身のデータ特性を見ながら必要な箇所は必要な桁数に絞るのがよいかなと思います。
おまけ
参考情報


コメント