
概要
OracleをRedshiftに移行するために、AWS SCT(Schema Conversion Tool)を使ってRedshift用のDDLを作成する手順の解説です。中身のレコードの移行については別記事で紹介させていただきます。
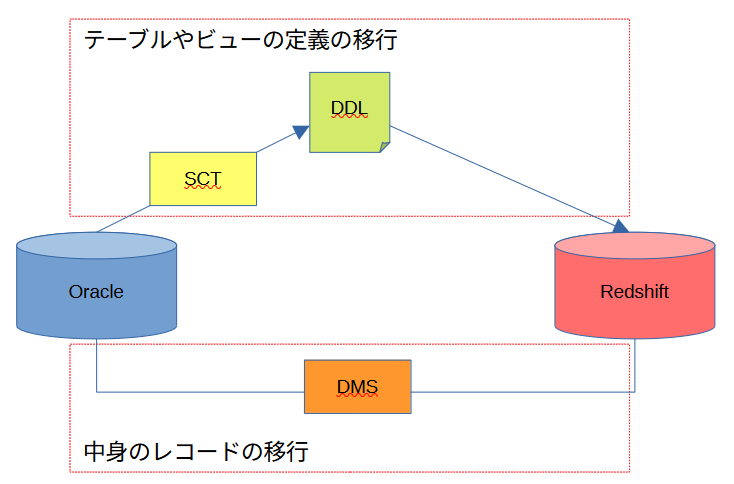
背景
OracleからRedshiftに移行するプロジェクトにあたりました。
SCTはツールを入れて実行すれば完成というほど賢いものではなかったので、得たノウハウの共有です。
やりかた
インストールする
とりあえずダウンロードしてきてインストールです。今回はWindowsに入れています。

インストールが終わるとデスクトップにショートカットができるので起動してみます。
AWS DMS Shema Conversionの紹介が表示されます。[Not now]をクリックします。
移行プロジェクトを作る
Fileから新しい移行プロジェクトを作ります。
適当に名前をつけて[OK]をクリックします。
移行元データベースを追加する
SCTで変換するには移行元を追加してあげる必要があります。
まずは移行元を追加します。[Add source]をクリックします。
[Oracle]を選択して[Next]を押します。

接続情報を入力して[Test connection]をクリックします。
| 項目名 | 値 | 備考 |
| Connection name | 任意 | |
| AWS Secret | 移行元がAWSでなければ触らなくていい | |
| Type | Service name | SIDではなくService Nameを使う |
| Server name | IPアドレスかホスト名 | |
| Server port | 1521 | |
| Service name | サービス名 | Oracleの評価版を入れているならXEPDB1 |
| User name | ログインできるユーザー名 | |
| Password | パスワード | |
| Oracle driver path | jdbcドライバのパス |

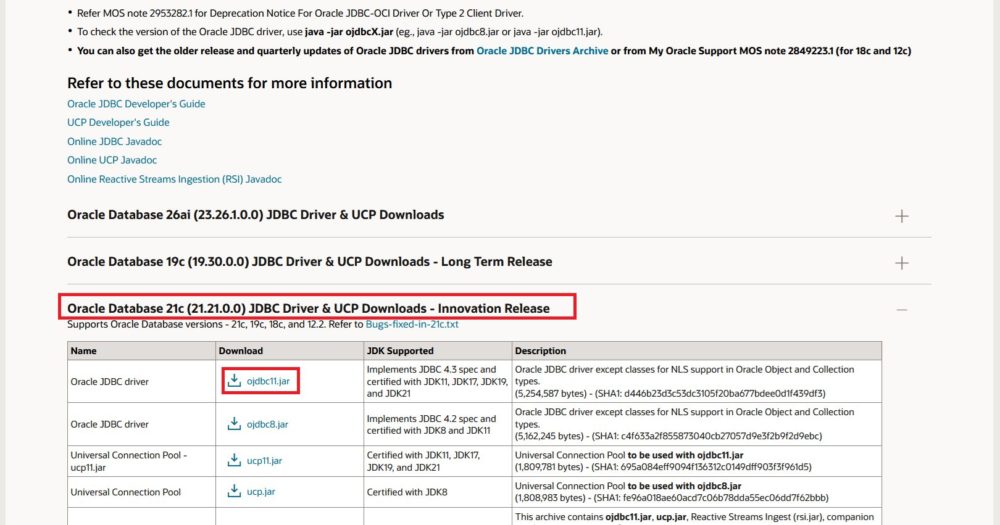
[Oracle driver path]はOracle JDBCドライバーのパスを指定します。持っていなければ次のページからバージョンにあったものを拾ってきてください。

今回繋ぐOracleは21cなので21cの中から選びます。version8以上であればよいそうですが折角なので新しそうな11にしました。
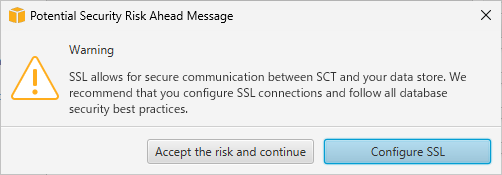
「SSLで繋ぎに行ったほうがいいよ」という警告が出ますが、今回は閉域のテスト環境なので[Accept the risk and continue]で進めます。
テストが問題なければ[Connect]をクリックします。
左側のツリーに移行元のデータベースが追加されました。
Mapping Ruleを作成する
OracleからRedshiftへ変換するMapping Ruleを作成します。
[Mapping view]を開き、左側の[Sources]ツリーから移行対象のスキーマを、右側の[Targets]ツリーから移行先のデータベースを選択し、[Create mapping]ボタンをクリックします。

Mapping Ruleが作成されました。
Migration Ruleを作成する
Migration Ruleは移行元と移行先が異るデータベースの場合に、データ型の変換や名前の変更など一手順入れるための機能です。
まず、Migration Ruleを作成する前に一度、Oracleで定義されたテーブルをRedshift用に変換してみます。移行元のOracleでは以下の定義でテスト用のテーブルを作成しています。
CREATE TABLE test_table (
id NUMBER PRIMARY KEY,
name char(10),
created_date DATE DEFAULT SYSDATE
);AWS SCTで[Main view]に移動し、左側の[Sources]ツリーから移行する[TEST_TABLE]を選択して右クリックします。
[Convert schema]をクリックします。
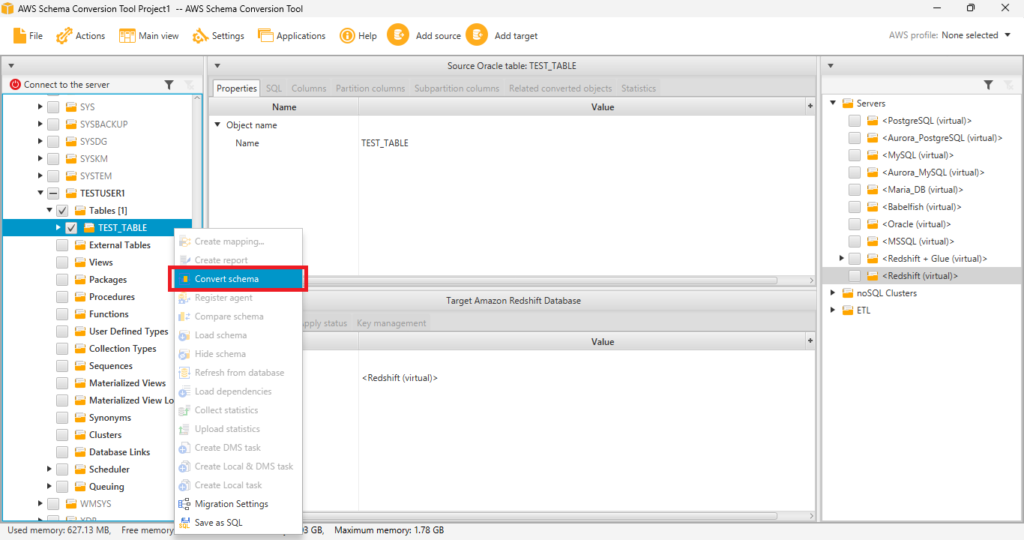
ターゲットデータベースを置き換えしていいか聞いてきます。ターゲットはvirtualなので置き換えてしまって大丈夫です。
少し待つと右側の[Targets]ツリーにOracleから変換された[test_table]が現れます。
テーブル名にチェックを入れて右クリックし、[Save as SQL]を選択します。
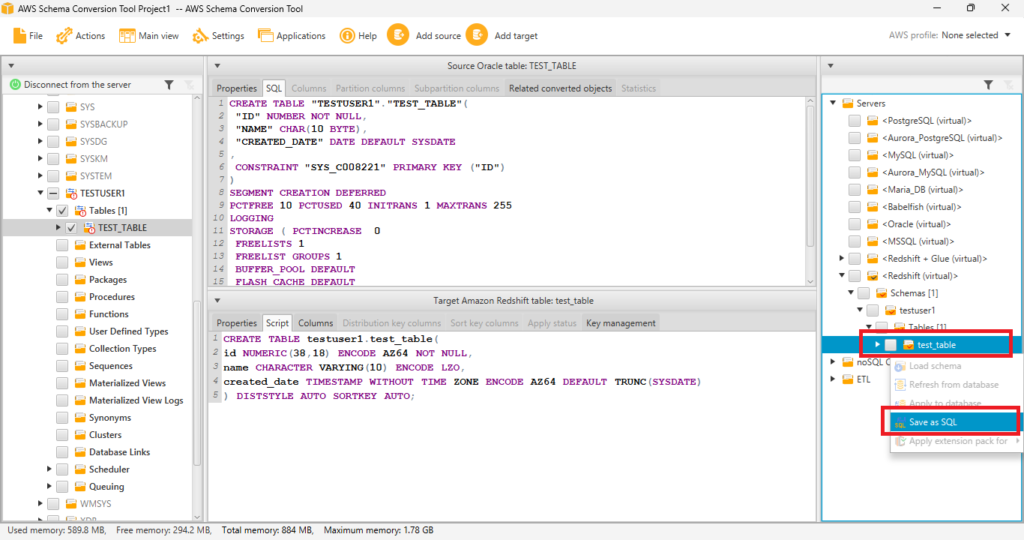
Redshiftにtest_tableを作成するためのSQLファイルが作れました。
-- ------------ Write DROP-CONSTRAINT-stage scripts -----------
ALTER TABLE testuser1.test_table DROP CONSTRAINT sys_c008221;
-- ------------ Write DROP-TABLE-stage scripts -----------
DROP TABLE IF EXISTS testuser1.test_table;
-- ------------ Write CREATE-DATABASE-stage scripts -----------
CREATE SCHEMA IF NOT EXISTS testuser1;
-- ------------ Write CREATE-TABLE-stage scripts -----------
CREATE TABLE testuser1.test_table(
id NUMERIC(38,18) ENCODE AZ64 NOT NULL,
name CHARACTER VARYING(10) ENCODE LZO,
created_date TIMESTAMP WITHOUT TIME ZONE ENCODE AZ64 DEFAULT TRUNC(SYSDATE)
) DISTSTYLE AUTO SORTKEY AUTO;
-- ------------ Write CREATE-CONSTRAINT-stage scripts -----------
ALTER TABLE testuser1.test_table
ADD CONSTRAINT sys_c008221 PRIMARY KEY (id);
このように、Migration ruleを作っていなくとも基本的にはSCTが良い感じの変換をしてくれます。
ではなぜMigration ruleを作ると言い出しているかと言うと、それぞれのCREATE文を見比べるとわかるのですが、「SCTの良い感じの変換」ではちょっと考慮が足りていない部分があるからです。
-- Oracle
name char(10),
-- Redshift
name CHARACTER VARYING(10) ENCODE LZO,OracleのCHAR型(固定長文字列)をRedshift用に変換するとCHARACTER VARYING型(可変長文字列)になっています。固定長可変長くらいは私は別にいいのですが、プロジェクトによってはこれも固定長になるようにMapping ruleを作成する必要があるでしょう。
それよりも困ったのはRedshiftのCHARACTER VARYING型におけるマルチバイト文字の扱いです。次の説明のとおりの動作をするようで、例えばOracleで2バイト文字の日本語10文字入れていたとすると、Redshiftでの定義では5文字までしか入らないということが起きます。
一定の制限を持つ可変長の文字列を格納するには、VARCHAR 列または CHARACTER VARYING 列を使用します。これらの文字列は空白で埋められないので、VARCHAR(120) 列は、最大で 120 個のシングルバイト文字、60 個の 2 バイト文字、40 個の 3 バイト文字、または 30 個の 4 バイト文字で構成されます。

このような問題を回避するために、Migration ruleで型変換を拡張してあげます。
[Mapping view]に戻り、[New migration rule]を作ります。
[Transformation rule]を選択します。
[Add new rule]をクリックします。
次の内容の設定を入れます。ここで定義したのは、任意のスキーマの任意のテーブルの任意のカラムに対して、移行元がCHAR型であればCHARACTER VARYING型に変換し、Lengthを元の3倍にする、というものです。3倍にしている理由はRedshiftで使われるUTF8のマルチバイト文字の最大が3バイトなのでOracleでどんな文字が入っていようと格納できるようにするためです。
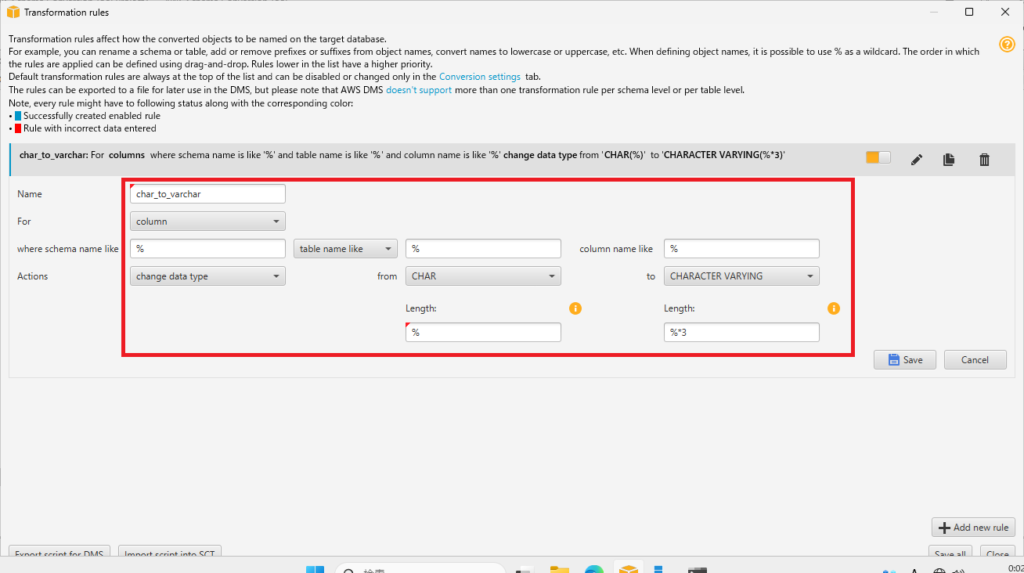
まず1つMigration ruleが作れたので[Save]して[Close]します。
[Mapping view]で追加したMigration ruleが見えるようになりました。
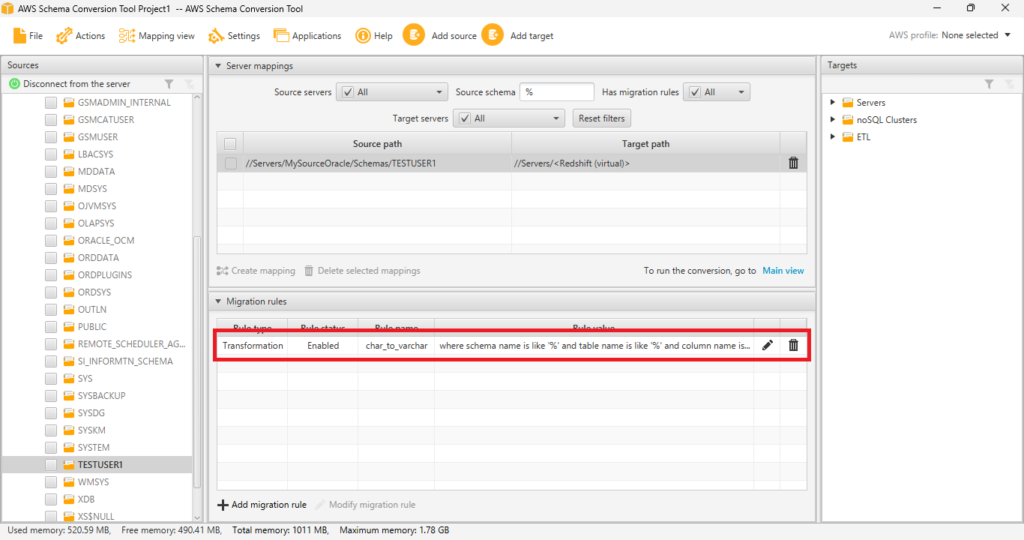
Redshift用のDDLを作成する
Migration Ruleも作れたので改めて[Main view]から[Convert schema]して、Redshift用のDDLを作成します。
出し直したものが次です。CHARACTER VARYING(30)になっているので大丈夫そうですね。これをRedshiftに適用すればDDLの移行は完了です。
-- ------------ Write DROP-CONSTRAINT-stage scripts -----------
ALTER TABLE testuser1.test_table DROP CONSTRAINT sys_c008221;
-- ------------ Write DROP-TABLE-stage scripts -----------
DROP TABLE IF EXISTS testuser1.test_table;
-- ------------ Write CREATE-DATABASE-stage scripts -----------
CREATE SCHEMA IF NOT EXISTS testuser1;
-- ------------ Write CREATE-TABLE-stage scripts -----------
CREATE TABLE testuser1.test_table(
id NUMERIC(38,18) ENCODE AZ64 NOT NULL,
name CHARACTER VARYING(30) ENCODE LZO,
created_date TIMESTAMP WITHOUT TIME ZONE ENCODE AZ64 DEFAULT TRUNC(SYSDATE)
) DISTSTYLE AUTO SORTKEY AUTO;
-- ------------ Write CREATE-CONSTRAINT-stage scripts -----------
ALTER TABLE testuser1.test_table
ADD CONSTRAINT sys_c008221 PRIMARY KEY (id);
おまけ
参考情報
AWS SCTでOracleデータベースへ接続する

AWS SCT用のJDBCドライバーのインストール

AWS SCTでの移行ルールの作成

SIDでなくService nameで接続する理由
SIDである”XE”を使って接続してみたところ、XEPDB1にあるスキーマが見えないということが起きました。詳しくはよくわかりませんが、移行対象のPDBにService nameで繋ぐのがよさそうです。
1テーブルずつDDLを作るのはめんどい
[Tables]を指定して[Save as SQL]すれば、配下のテーブル全てを含んだ1つのSQLファイルを作ってくれます。

ビューのDDLも作りたい
テーブルと同じように、左側の[Sources]ツリーで[Convert schema]して、右側の[Targets]ツリーで[Save as SQL]をすれば作れます。
プロシージャとかも作りたい
方法は同じはずですが、今回のプロジェクトではプロシージャは移行対象外とさせていただきました。正直、ビューのあたりからSCTの動きに不信感があったので、複雑なものをこれで移行するのはかなり厳しいのではないかと思います。

コメント